The Case for Going Parallel
Ever since the first computer was invented, humans here wanted to increase the speed of these machines. And whenever we speak on performance of computers, we need to talk about the Moore's Law1. It basically states that the number of transistors we are able to fit on a chip will double roughly every 24 months. Theoretically, this implies that the speed will also double2. At the beginning, about the whole task of increasing performance of computers was left for hardware developers–software developers stayed clear of it for the most part. Then, we had to start thinking about power. According to a study done by Edgar Grochowsky3, the power consumption of new chips grew almost quadratically through the years, revealing a completely unsustainable power model–the power wall. What ensued was a radical redesign and optimization of the chip architecture for power (with little impact on performance). Following is a glance at some of the silicon(y) bits that were involved.
C = q / V
Capacitance (C) is a measurement of the ability of a chip to store energy. So, capacitance is equal to the charge (q) a circuit holds divided by its voltage (V). We know that work (W)4 is moving a charge against a voltage. So, work is voltage times charge.
W = V * q
From above two equations, we get that work is capacitance times the square of voltage.
W = CV2
How can we go from work to power? Well, power is work per unit time (ie. how many times in a second we oscillate the circuit). That is, work times the frequency (F) is going to give us the power (frequency is one over time).
Power = W * F
When we put all that together, we get that power is capacitance times the square of voltage times the frequency. Below equation is very important as we understand what is happening in computer architecture today.
Power = CV2F
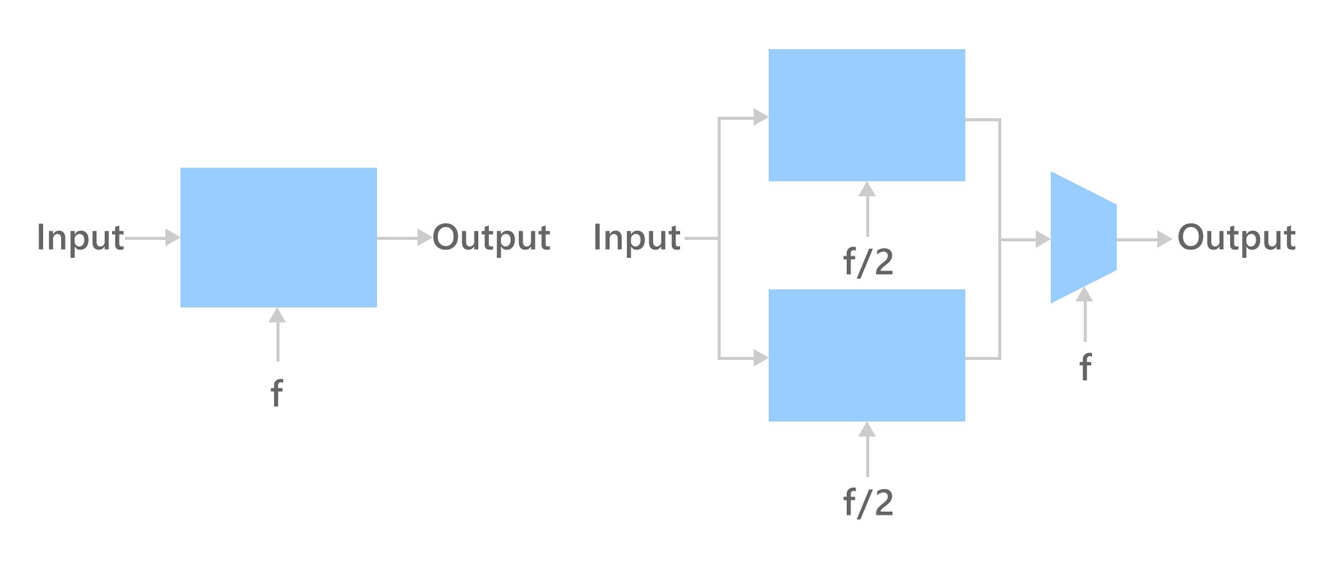 Two chip architectures
Two chip architectures
In the left one of above two architectures, we are driving some input through a chip with some output at frequency F, requiring power P = CV2F. On the other (right), we have two cores on the same chip, but we are driving them at half the frequency (F / 2). However, since we have more wires here, we don’t just double the capacitance, but increase it even a little more (C * 2.2). Frequency scales with voltage, but since there is leakage and other things going on, let’s assume the voltage goes not half, but a little more than that (V * 0.6). If we now plug that into the equation we derived above we find that power goes down in this half-frequency case about 40% (P * 0.396).
That means, for a given input F with one core versus F / 2 with two cores we are getting the same output. But with two cores we are getting 40% power. This is why we do computing in parallel, because it gives us the ability to get the same amount of work done with multiple cores at a lower frequency with a tremendous power saving.
That is why everyone in the industry is putting more and more cores in a small piece of silicon. This introduces a new dynamic–hardware developers will do whatever they want, software developers should deal with it. Performance has to come from software. It means you need to go into your software and make it run in parallel. However, we have still failed to create a compiler that takes in serial code and makes it parallel for us, which means we will have to do it ourselves.
Concurrency vs Parallelism
Concurrency is a condition of a system in which multiple tasks are logically active at one time. Parallelism is a condition of a system in which multiple tasks are actually active at one time.
 Concurrent, non-parallel execution
Concurrent, non-parallel execution
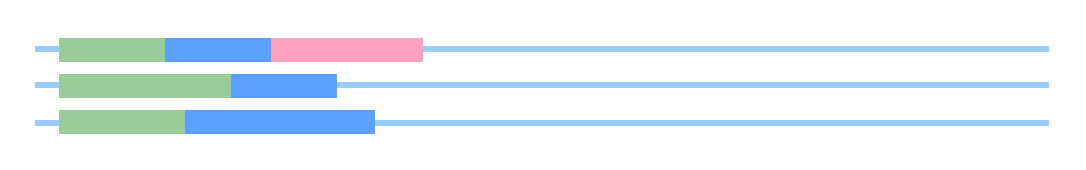 Concurrent, parallel execution
Concurrent, parallel execution
We need to expose concurrency in a problem, then map it into processing units so they actually execute at the same time–that is parallelism. That is, we have the universal set of programs, a subset of concurrent programs, and then parallel programs as a subset of it, as shown below.
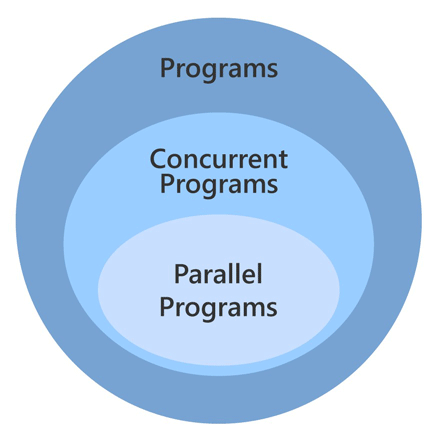 Programs venn-diagram
Programs venn-diagram
A concurrent application has concurrency built into the problem definition. Take a web server. It would hardly make sense to develop a web server that can only take a serial sequence of inputs. So that is a concurrent application that is designed to be concurrent from the beginning. In parallel applications, there are things happening at the same time to make it run faster, or to make it run the same amount of time but handle a bigger problem.
That is, in a concurrent application, there is no way to define the problem without concurrency. In a parallel application though, we could talk about doing it without concurrency.
So, when writing parallel programs, finding the concurrency and understanding the algorithm strategy is the way to start. Choosing what parallel programming language we should use is a comparably trivial step that only comes afterward.